🌀 Trong ví dụ với dữ liệu mô phỏng này, ta sẽ dùng SVM với kernel RBF để phân loại hai lớp có dạng vòng tròn chồng nhau – bài toán không tuyến tính. Mô hình được huấn luyện trên dữ liệu giả lập và đạt độ chính xác cao, sau đó vẽ ranh giới phân loại để thể hiện khả năng “uốn cong” đường chia lớp của SVM. Một cách trực quan để hiểu sức mạnh của kernel phi tuyến!
🧪 1. Tạo dữ liệu dạng vòng tròn (không tuyến tính):
X, y = datasets.make_circles(n_samples=300, factor=0.3, noise=0.1, random_state=42)
- Tạo 300 điểm thuộc 2 vòng tròn lồng nhau (class 0 và 1).
factor=0.3: vòng tròn trong có bán kính nhỏ hơn.noise=0.1: thêm nhiễu để làm bài toán thực tế hơn.
→ Đây là bài toán không tuyến tính, buộc mô hình phải “uốn cong” ranh giới ra quyết định.
✂️ 2. Chia dữ liệu thành tập huấn luyện và kiểm tra:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
- 70% huấn luyện, 30% kiểm tra.
⚙️ 3. Khởi tạo và huấn luyện SVM:
model = SVC(kernel='rbf', gamma='scale') model.fit(X_train, y_train)
kernel='rbf'(Radial Basis Function): dùng để phân biệt dữ liệu không tuyến tính.gamma='scale': tự động điều chỉnh độ ảnh hưởng của từng điểm.
🎯 4. Dự đoán & đánh giá:
y_pred = model.predict(X_test) accuracy_score(y_test, y_pred)
- Dự đoán nhãn trên tập kiểm tra.
- Tính độ chính xác (accuracy) → ví dụ: 0.97 là rất tốt.
🖼️ 5. Vẽ ranh giới phân loại (decision boundary):
plot_decision_boundary(model, X_test, y_test)
- Vẽ lưới điểm trên không gian 2D.
- Dự đoán lớp từng điểm trong lưới → dựng contour thể hiện vùng phân loại.
- Vẽ scatter các điểm thực tế để thấy mô hình phân loại thế nào.
✅ Kết quả:
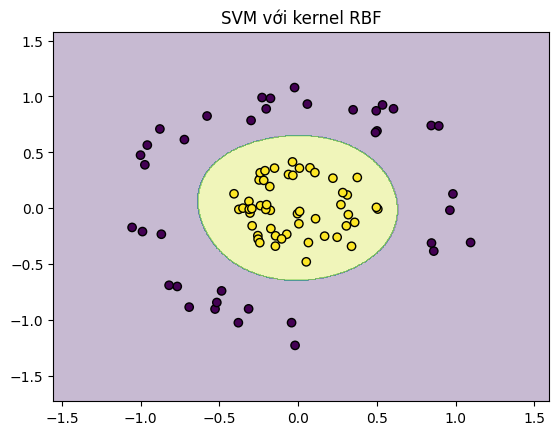
- Dữ liệu
make_circleslà điển hình cho bài toán đòi hỏi kernel mạnh mẽ. - Đồ thị phân loại cho thấy mô hình “bẻ cong” biên hiệu quả để chia hai lớp vòng tròn.
Toàn bộ code:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
# Tạo dữ liệu giả (hai lớp)
X, y = datasets.make_circles(n_samples=300, factor=0.3, noise=0.1, random_state=42)
# Chia dữ liệu thành train/test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Khởi tạo mô hình SVM với kernel RBF
model = SVC(kernel='rbf', gamma='scale')
# Huấn luyện
model.fit(X_train, y_train)
# Dự đoán
y_pred = model.predict(X_test)
# Đánh giá
print(f"Accuracy: {accuracy_score(y_test, y_pred):.2f}")
# Vẽ đồ thị
import numpy as np
def plot_decision_boundary(model, X, y):
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 500), np.linspace(y_min, y_max, 500))
Z = model.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, alpha=0.3)
plt.scatter(X[:, 0], X[:, 1], c=y, edgecolors='k')
plt.title("SVM với kernel RBF")
plt.show()
plot_decision_boundary(model, X_test, y_test)