🌳 Cây Quyết Định (Decision Tree) là một thuật toán học máy phổ biến dùng để phân loại hoặc hồi quy. Nó hoạt động bằng cách chia dữ liệu thành các nhánh dựa trên điều kiện, giống như cách con người ra quyết định.
Dưới đây là một ví dụ đơn giản sử dụng DecisionTreeClassifier từ thư viện scikit-learn trên bộ dữ liệu Iris. Bộ dữ liệu Iris là tập hợp 150 mẫu hoa của ba loài Iris — setosa, versicolor, và virginica — mỗi mẫu gồm 4 đặc trưng đo lường về chiều dài và chiều rộng đài hoa (sepal) và cánh hoa (petal) dùng để phân loại loài hoa.
from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier from sklearn import tree import matplotlib.pyplot as plt # Tải dữ liệu mẫu Iris iris = load_iris() X, y = iris.data, iris.target # Khởi tạo cây quyết định và huấn luyện model = DecisionTreeClassifier() model.fit(X, y) # Vẽ cây quyết định plt.figure(figsize=(12, 8)) tree.plot_tree(model, feature_names=iris.feature_names, class_names=iris.target_names, filled=True) plt.show()
🔍 Giải thích nhanh:
load_iris()nạp tập dữ liệu mẫu về hoa Iris.DecisionTreeClassifier()là mô hình phân loại theo cây quyết định.fit()huấn luyện mô hình với dữ liệu.plot_tree()vẽ ra cây trực quan để dễ hiểu cách mô hình phân loại.
kết quả:
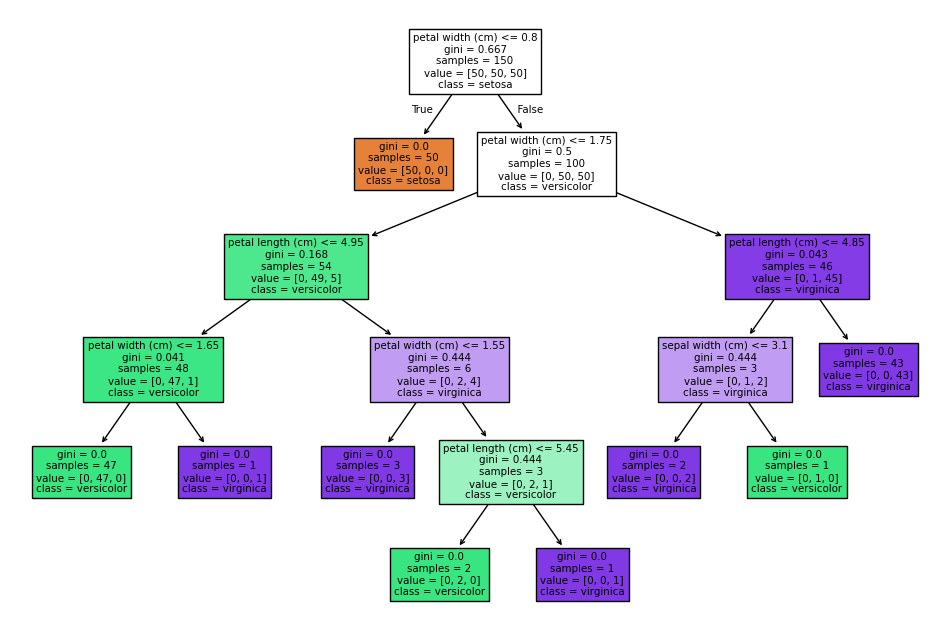
Cây này nhìn chỉa tứ tung, nên chúng ta cần phải cắt tỉa (prune).
🌿 Pruning (cắt tỉa cây quyết định) giúp giảm độ phức tạp của mô hình, tránh hiện tượng quá khớp (overfitting). Có hai cách chính:
- Pre-pruning (cắt tỉa trước): Dừng cây sớm bằng cách giới hạn độ sâu, số mẫu tối thiểu…
- Post-pruning (cắt tỉa sau): Huấn luyện cây đầy đủ rồi lược bỏ những nhánh không cần thiết.
Muốn cây mượt như bonsai hay mọc um tùm như rừng Amazon là tùy bạn 😄. Bạn muốn cây càng đơn giản càng tốt hay giữ độ chính xác cao hơn?
Code cắt tỉa nghệ thuật trong Python dùng pre-pruning với max_depth:
from sklearn.datasets import load_iris from sklearn.tree import DecisionTreeClassifier, plot_tree import matplotlib.pyplot as plt # Tải dữ liệu iris = load_iris() X, y = iris.data, iris.target # Áp dụng pre-pruning bằng cách giới hạn độ sâu tối đa model = DecisionTreeClassifier(max_depth=3) model.fit(X, y) # Vẽ cây sau khi cắt tỉa plt.figure(figsize=(12, 8)) plot_tree(model, feature_names=iris.feature_names, class_names=iris.target_names, filled=True) plt.show()
kết quả
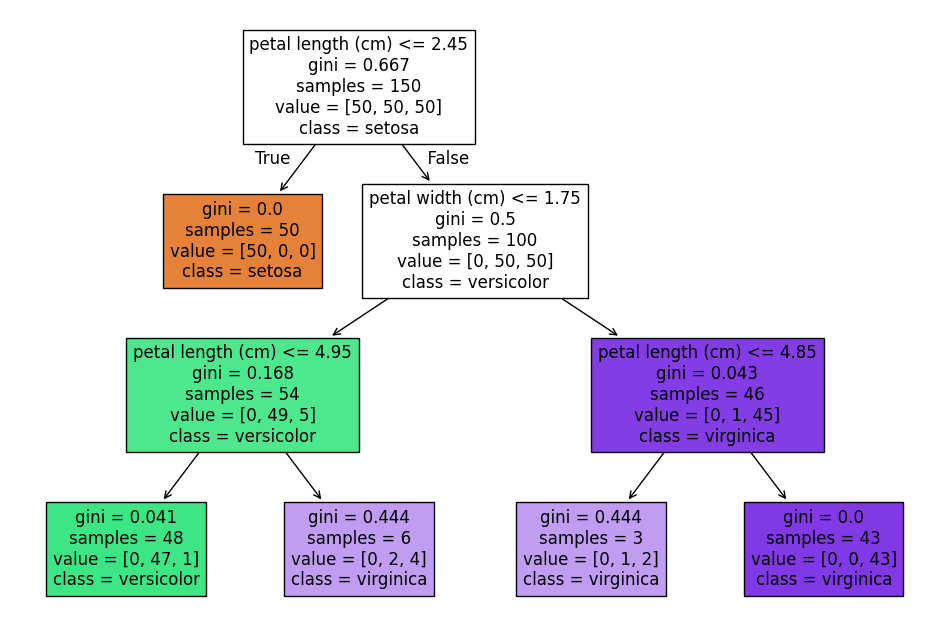
📊 Diễn giải kết quả cây quyết định:
Cây quyết định trong ảnh phân loại 3 loại hoa Iris: setosa, versicolor, và virginica, dựa trên các đặc trưng như chiều dài/canh hoa (petal) và đài hoa (sepal).
🌿 Tổng quan cách cây hoạt động:
- Mỗi nút trong cây biểu diễn một điều kiện phân nhánh, ví dụ:
petal width <= 0.8. - Tại mỗi nút có thông tin:
- Gini: độ thuần khiết của phân phối (0 là thuần nhất, càng gần 0 càng tốt).
- Samples: số lượng mẫu tại nút đó.
- Value: số mẫu của từng lớp
[setosa, versicolor, virginica]. - Class: nhãn được dự đoán nếu mẫu dừng lại ở nút đó.
🌸 Các nhánh quan trọng:
- Gốc cây: nếu
petal width <= 0.8→ tất cả là setosa (50 mẫu), vìgini = 0. - Nhánh phải (petal width > 0.8):
- Tiếp tục phân chia theo
petal length <= 1.75→ giúp tách versicolor và virginica. - Những nút có
ginithấp như:petal length <= 4.95vàpetal width <= 1.65→ hầu hết là versicolorpetal length > 4.85→ gần như toàn bộ là virginica
- Tiếp tục phân chia theo
👉 Cây này khá chính xác, vì:
- Có nhiều nút với
gini = 0.0, tức là phân loại hoàn hảo tại đó. - Các ngưỡng chia tách rất hiệu quả: đặc biệt là chiều dài và chiều rộng cánh hoa (petal).
📌 Lưu ý thêm:
min_samples_split,min_samples_leaf,max_leaf_nodescũng là tham số pruning hữu ích.- Với post-pruning,
Cost Complexity Pruningcó thể thực hiện bằngccp_alphatrongDecisionTreeClassifier.
Ví dụ 2: Breast Cancer
Bộ dữ liệu Breast Cancer Wisconsin là một tập dữ liệu phổ biến cho các bài toán phân loại, đặc biệt là phân biệt giữa khối u ác tính (malignant) và lành tính (benign). Ta có thể xây dựng cây quyết định để dự đoán loại khối u dựa trên các đặc trưng như độ nhẵn, đường kính, mật độ…
Dưới đây là ví dụ sử dụng DecisionTreeClassifier và load_breast_cancer:
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# Tải dữ liệu
data = load_breast_cancer()
X = data.data
y = data.target
# Chia dữ liệu thành tập huấn luyện và kiểm tra
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
# Huấn luyện cây quyết định
model = DecisionTreeClassifier(max_depth=4, random_state=0)
model.fit(X_train, y_train)
# Vẽ cây quyết định
plt.figure(figsize=(20, 10))
plot_tree(model, feature_names=data.feature_names, class_names=data.target_names, filled=True)
plt.title("Decision Tree - Breast Cancer Classification")
plt.show()
🧠 Giải thích nhanh:
max_depth=4: giới hạn độ sâu để tránh overfitting.data.feature_names: gồm 30 đặc trưng nhưmean radius,mean texture,worst area, v.v.data.target_names: gồmmalignantvàbenign.
🌟 Chọn tự động giá trị ccp_alpha tối ưu cho cây phân loại dựa trên tập dữ liệu Breast Cancer
Dưới đây là ví dụ chọn alpha tối ưu bằng cách đánh giá độ chính xác (accuracy_score) của các mô hình với các giá trị alpha khác nhau:
from sklearn.datasets import load_breast_cancer
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Tải dữ liệu
data = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, random_state=42)
# Huấn luyện cây đầy đủ và lấy đường pruning
clf = DecisionTreeClassifier(random_state=0)
path = clf.cost_complexity_pruning_path(X_train, y_train)
ccp_alphas = path.ccp_alphas[:-1] # Loại bỏ alpha cuối cùng (cây trống)
# Tìm alpha cho mô hình có độ chính xác cao nhất
best_alpha = None
best_model = None
best_score = 0
for alpha in ccp_alphas:
model = DecisionTreeClassifier(ccp_alpha=alpha, random_state=0)
model.fit(X_train, y_train)
score = accuracy_score(y_test, model.predict(X_test))
if score > best_score:
best_score = score
best_model = model
best_alpha = alpha
print(f"✅ Alpha tối ưu là: {best_alpha:.5f} với độ chính xác: {best_score:.4f}")
📌 Giải thích nhanh:
cost_complexity_pruning_path()tìm các giá trịccp_alphakhả dụng để prune cây.- Vòng lặp huấn luyện nhiều cây tương ứng với các alpha và chọn cây có
accuracy_scorecao nhất trên tập test.
kết quả

🔍 Phân tích kết quả cây quyết định với dữ liệu ung thư vú (Breast Cancer Dataset):
Cây trong ảnh là mô hình phân loại khối u lành tính (benign) hoặc ác tính (malignant) dựa trên đặc trưng “mean concave points”.
🧠 Nút gốc (root node):
- 📌 Điều kiện chia:
mean concave points ≤ 0.051 - 🧮 Gini = 0.467 → phân phối chưa thuần nhất
- 🔢 Mẫu: 426, với
[158 malignant, 268 benign] - 💡 Lớp dự đoán:
benign(chiếm số đông)
🌿 Nhánh trái (True branch) — nếu concave points ≤ 0.051:
- Gini = 0.113 → gần như thuần nhất
- Mẫu = 267 →
[16 malignant, 251 benign] - Dự đoán:
benign
→ Đây là vùng rất đáng tin cậy để phân loại khối u lành tính.
🔥 Nhánh phải (False branch) — nếu concave points > 0.051:
- Gini = 0.191 → vẫn khá thuần
- Mẫu = 159 →
[142 malignant, 17 benign] - Dự đoán:
malignant
→ Nút này cũng thể hiện khả năng phân biệt khối u ác tính hiệu quả.
🧪 Ý nghĩa đặc trưng “mean concave points”:
Đây là chỉ số đo độ lõm tại các biên của khối u trên ảnh chụp, giá trị càng cao thường liên quan đến độ bất thường — giúp phân biệt giữa khối u ác và lành.
✅ Tổng kết đánh giá mô hình:
- Việc chia nhánh chỉ bằng 1 đặc trưng duy nhất cho thấy dữ liệu có tính phân biệt mạnh.
- Gini thấp ở các nút con → khả năng phân loại tốt.
- Cây gọn, dễ hiểu, thích hợp để giải thích y khoa hoặc ứng dụng thực tế.